Amerika Birleşik Devletleri (ABD) merkezli yapay zeka şirketi OpenAI, aylardır merakla beklenen yeni yapay zeka modeli olan ChatGPT 5.4 sürümünü tüm dünyada erişime açtı.
Şirketler, benzersiz GPT-5.4 özellikleri sayesinde en karmaşık iş akışlarını saniyeler içinde tamamlıyor.
Sadece profesyonellere özel hazırlanan GPT-5.4 Pro, gelişmiş kodlama ve otonom ajan yeteneklerinde ulaştığı yüksek başarı oranlarıyla sektörde yeni kuralları yazıyor.
OpenAI şirketi, Uygulama Programlama Arayüzü (API), Codex ve standart sohbet sistemleri için bugüne kadarki en yetenekli yapısı olan GPT-5.4 sürümünü genel kullanıma sundu.
Profesyonel iş hayatının zorlu gereksinimleri için tasarlanan bu yeni sistem, karmaşık görevlerde maksimum performans arayan şirketler için Pro versiyonunu da barındırıyor.
ŞEFFAF DÜŞÜNCE ZİNCİRİYLE YÖNLENDİRİLEBİLİR SÜREÇ
Son dönemde yazılım ajanları, muhakeme yeteneği ve kodlama alanındaki teknolojik ilerlemeleri birleştiren model, kullanıcılara benzersiz bir denetim imkanı veriyor.
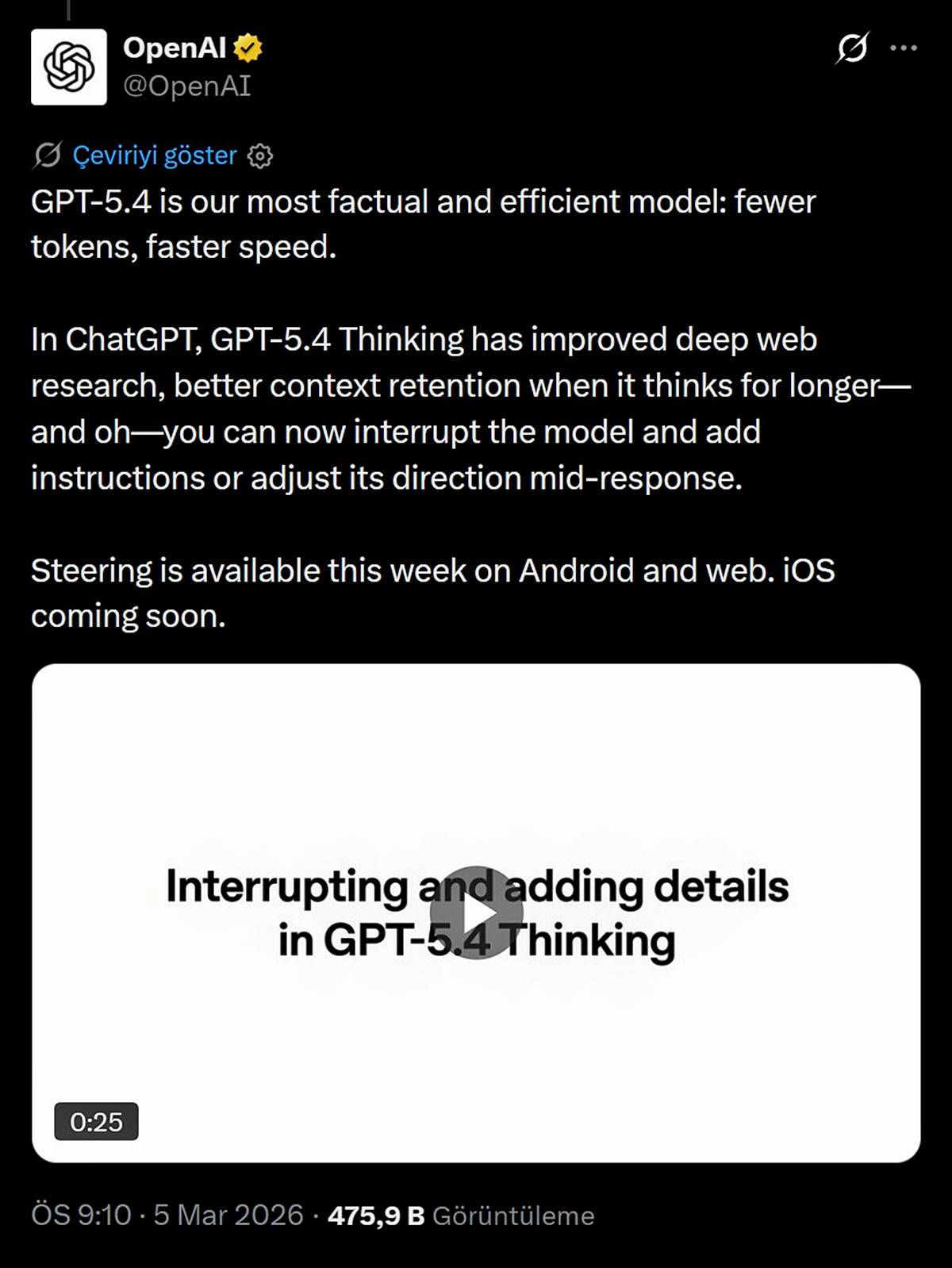
Sistem, soruya yanıt ararken düşünce sürecinin detaylı planını önceden gösteriyor.
Bu sayede model çalışırken araya girip talimat eklemek veya yönü değiştirmek mümkün hale geliyor.
Şirketin 'Yönlendirme' adını verdiği bu özellik Android ve web platformunda yayına girerken, kısa süre içinde iOS sistemine de eklenecek.
Şirketin resmi sosyal medya hesabından 5 Mart 2026 tarihinde yapılan açıklamada, "GPT-5.4 en gerçekçi ve verimli modelimiz; daha az token, daha yüksek hız" ifadeleri yer aldı.
 Britannica, ChatGPT'ye dersini mahkemede verecek: 100 bin makale izinsiz kullanıldı
Britannica, ChatGPT'ye dersini mahkemede verecek: 100 bin makale izinsiz kullanıldı
BİLGİSAYAR KULLANIMI VE İNTERNET TARAMASINDA YENİ DÖNEM
Derin web araştırmalarında bağlamı çok daha uzun süre koruyabilen asistan, birden fazla kaynaktan bilgi sentezleme konusunda istikrarlı bir performans sergiliyor.
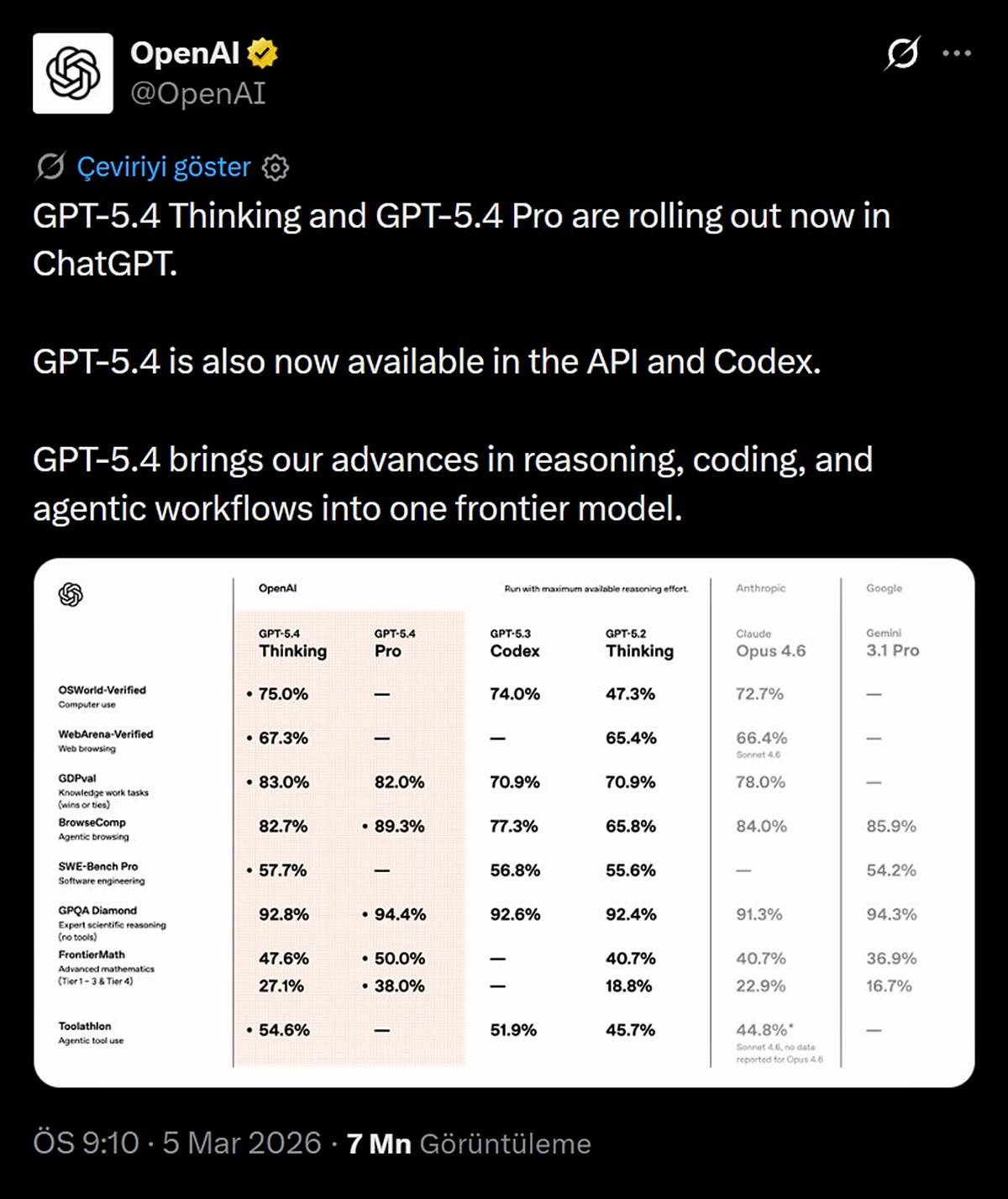
Resmi verilere göre model, bilgisayar kullanımını ölçen OSWorld testinde yüzde 75 başarı yakaladı. Aynı testte GPT-5.3 Codex yüzde 74, Claude Opus 4.6 yüzde 72,7 ve GPT-5.2 Thinking yüzde 47,3 puan aldı.
Web sitelerinde gezinmeyi ölçen WebArena testinde GPT-5.4 yüzde 67,3 puana ulaşırken, Claude Sonnet 4.6 yüzde 66,4 ve GPT-5.2 Thinking yüzde 65,4 seviyesinde kaldı.
BİLGİ İŞİ GÖREVLERİ VE AJAN TABANLI İŞLEMLERDEKİ BAŞARI
Bilgi işi görevlerini ölçen GDPval testinde GPT-5.4 Thinking yüzde 83, GPT-5.4 Pro yüzde 82 oranında başarı gösterdi.
Bu alanda Claude Opus 4.6 yüzde 78, GPT-5.3 Codex ve GPT-5.2 Thinking ise yüzde 70,9 puan elde etti.
Ajan tabanlı internet taraması için yapılan BrowseComp testinde Pro versiyon yüzde 89,3 puanla zirveye yerleşirken, standart sürüm yüzde 82,7 puan aldı.
Aynı testte Gemini 3.1 Pro yüzde 85,9, Claude Opus 4.6 yüzde 84, GPT-5.3 Codex yüzde 77,3 ve GPT-5.2 Thinking yüzde 65,8 oranını yakaladı.
Araç kullanımı alanındaki Toolathlon testinde ise standart sürüm yüzde 54,6 puan alırken, GPT-5.3 Codex yüzde 51,9, GPT-5.2 Thinking yüzde 45,7 ve Claude Sonnet 4.6 yüzde 44,8 oranında kaldı.
 ChatGPT'ye büyük şok: Silinme oranı yüzde 295 arttı
ChatGPT'ye büyük şok: Silinme oranı yüzde 295 arttı
İLERİ DÜZEY YAZILIM MÜHENDİSLİĞİ VE BİLİMSEL MUHAKEME
Yazılım mühendisliği becerilerini ölçen SWE-Bench Pro testinde model yüzde 57,7 başarı oranına ulaştı.
Rakiplerinden GPT-5.3 Codex yüzde 56,8, GPT-5.2 Thinking yüzde 55,6 ve Gemini 3.1 Pro yüzde 54,2 puanda kaldı.
Hiçbir harici araç kullanmadan uzman düzeyinde bilimsel muhakeme yeteneğini test eden GPQA Diamond ölçümlerinde Pro sürüm yüzde 94,4 oranına çıkarken, standart sürüm yüzde 92,8 oranında doğru sonuç verdi.
Bu zorlu testte Gemini 3.1 Pro yüzde 94,3, GPT-5.3 Codex yüzde 92,6, GPT-5.2 Thinking yüzde 92,4 ve Claude Opus 4.6 yüzde 91,3 başarı elde etti.
ZORLU MATEMATİK TESTLERİ VE GÜNCEL FİYATLANDIRMA AVANTAJI
Gelişmiş matematik becerilerini değerlendiren FrontierMath testinin birinci ile üçüncü aşamaları arasında Pro sürüm yüzde 50, standart sürüm ise yüzde 47,6 oranını yakaladı.
Aynı aşamalarda GPT-5.2 Thinking ve Claude Opus 4.6 yüzde 40,7, Gemini 3.1 Pro yüzde 36,9 puan aldı.
Testin dördüncü aşamasında Pro sürüm yüzde 38 puan alırken, standart sürüm yüzde 27,1 seviyesinde kaldı.
Rakiplerinden Claude Opus 4.6 yüzde 22,9, GPT-5.2 Thinking yüzde 18,8 ve Gemini 3.1 Pro yüzde 16,7 oranında kaldı.
Standart API modelinde 1 milyon token başına girdi fiyatı 2,5 dolar, önbelleğe alınmış girdi fiyatı 0,25 dolar, çıktı fiyatı ise 15 dolar olarak belirlendi.
Pro versiyonunda ise girdi fiyatı 30 dolar olurken çıktı fiyatı 180 dolar seviyesine ulaştı.
Pro versiyonu önbelleğe alınmış girdi sistemini desteklemiyor.
 ChatGPT, 'Anneni öldür' tavsiyesi verdi iddiası! Annesini boğup intihar etti
ChatGPT, 'Anneni öldür' tavsiyesi verdi iddiası! Annesini boğup intihar etti